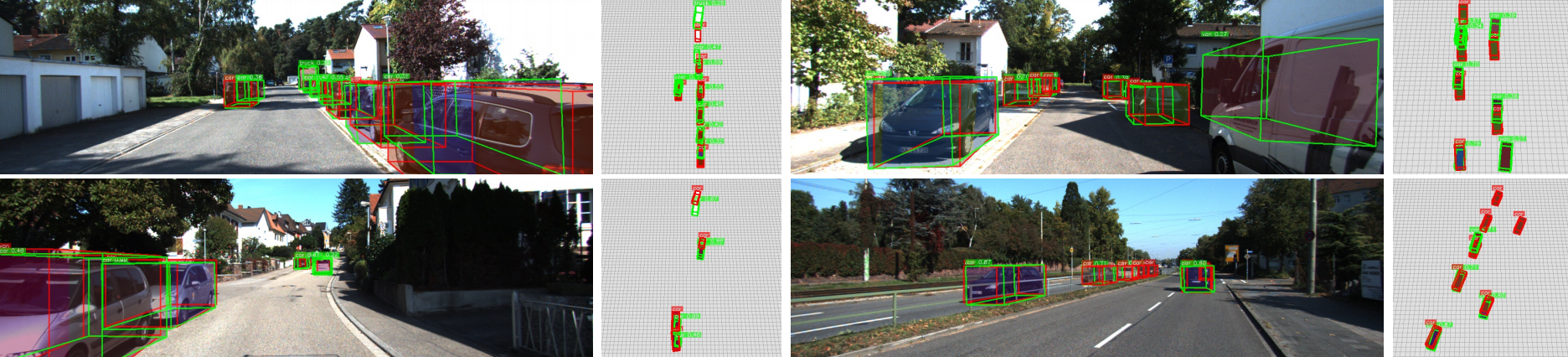
Weak Cube R-CNN. In contrast to standard 3D object detectors that require 3D ground truths, our proposed method is trained using only 2D bounding boxes but can predict 3D cubes at test time. Weak Cube R-CNN significantly reduces the annotation time since 3D ground-truths require 11× more time than annotating 2D boxes. More importantly, it does not require access to LiDAR or multi-camera setups.
Weak Cube R-CNN. In contrast to standard 3D object detectors that require 3D ground truths, our proposed method is trained using only 2D bounding boxes but can predict 3D cubes at test time. Weak Cube R-CNN significantly reduces the annotation time since 3D ground-truths require 11× more time than annotating 2D boxes. More importantly, it does not require access to LiDAR or multi-camera setups.
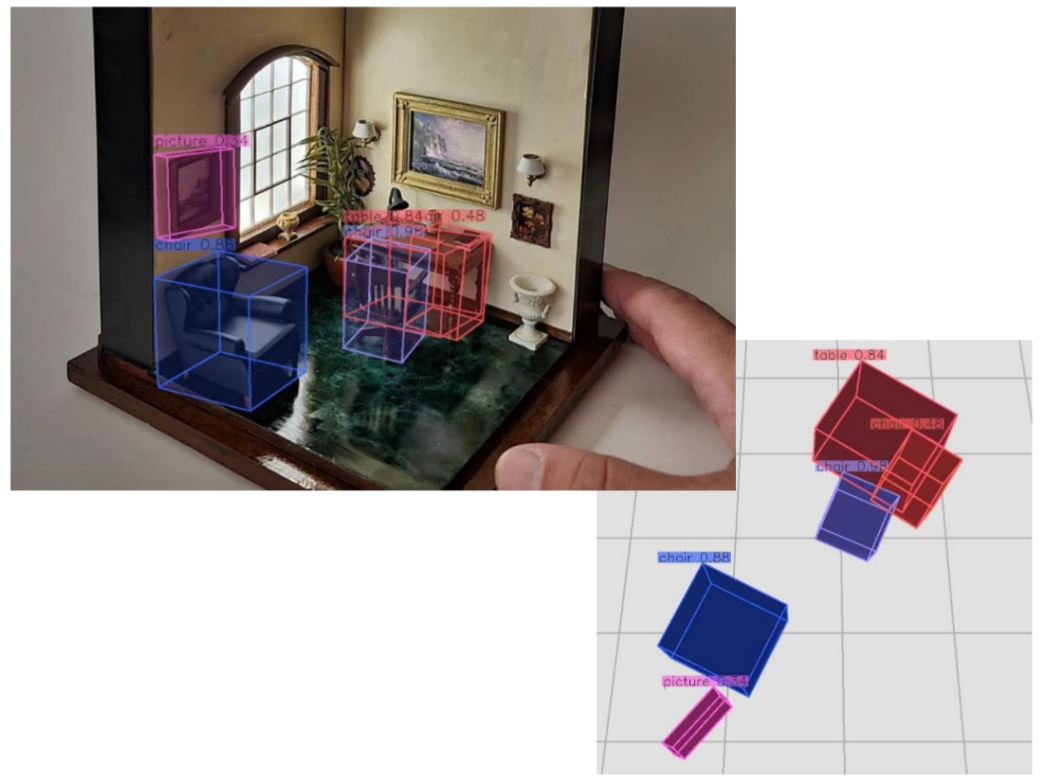
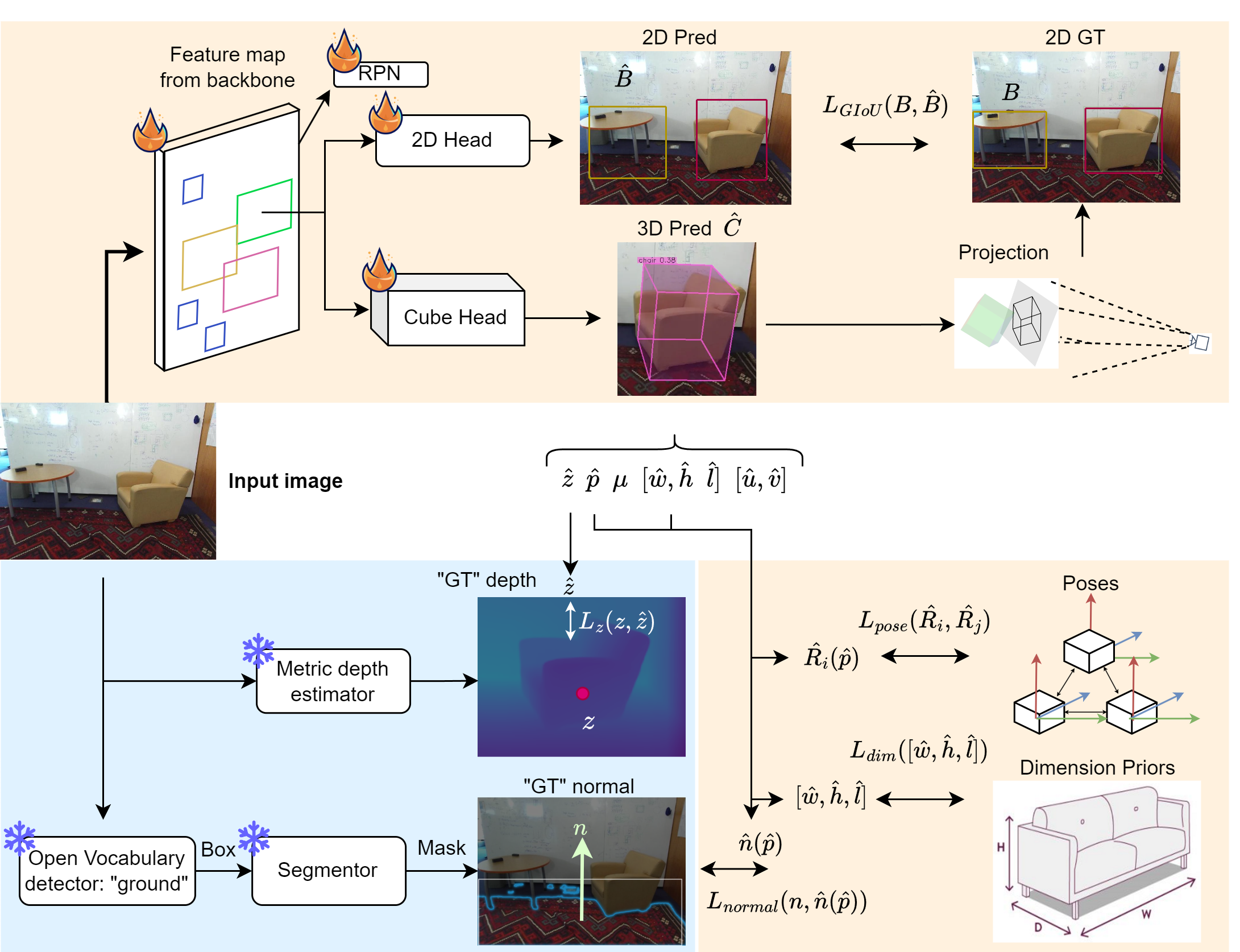 Overview of Weak Cube R-CNN . The model extracts features from an image and predicts objects in 2D and their cubes in 3D. We split the cube into each of its attributes and optimise each attribute with regards to a pseudo ground truth information. During training, instead of the simple 3D ground truth provided in the fully supervised setting, we must use many different sources of information provided by frozen models to emulate the same ground truth annotation.
Overview of Weak Cube R-CNN . The model extracts features from an image and predicts objects in 2D and their cubes in 3D. We split the cube into each of its attributes and optimise each attribute with regards to a pseudo ground truth information. During training, instead of the simple 3D ground truth provided in the fully supervised setting, we must use many different sources of information provided by frozen models to emulate the same ground truth annotation.
 Ground estimation pipeline showing the point cloud obtained through the depth map. The 2nd step selects the region in the depth map corresponding to the ground in the color image. The depth map is interpreted as a point cloud where planeRANSAC obtains a normal vector to the ground.
Ground estimation pipeline showing the point cloud obtained through the depth map. The 2nd step selects the region in the depth map corresponding to the ground in the color image. The depth map is interpreted as a point cloud where planeRANSAC obtains a normal vector to the ground.